前回から引き続き、PSIの謎(?)を追う。
まず、前回の id:hiboma さんのコメントにお返事する形で、そもそものPSIの値がどういうものかのお話を。
PSIをLXCのコンテナで試す: その(1) CPU Pressure - ローファイ日記b.hatena.ne.jp便利そう. 縦軸の value の単位は何になるんですかね?
2019/02/15 13:07
valueは cpu.pressure のファイルに出される値をそのまま使っている。この値が何者かについては、PSIの公式サイトに定義がある。単位時間内で(CPU、メモリ、IOいずれかの)リソースの不足が原因で処理に遅れが出ているタスクが発生した時間帯の割合、という定義になるとのこと。
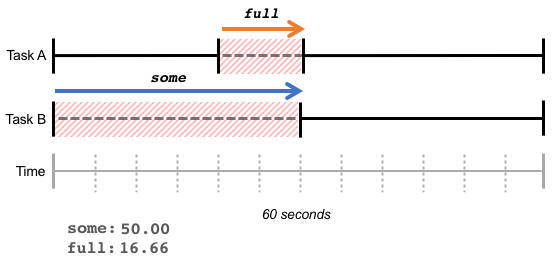
someの行は「1つ以上のタスクが」、fullの行は「全てのタスクが」遅延した時間の割合が出される。CPUでfullの行がないのは、全タスクにCPUリソースが割り振られないという状態は基本的にはないからだと思う(しかしcgroup内だとありそうだけど、どうなんだろうか...)。
したがって、過去10秒/60秒/300秒間の値を表示するなどLoad Averageを彷彿とさせるが、若干性質の違う値であることに留意したい。例えば100を超えることはないなど。
公式の説明図がわかりやすい。
で、もう少し条件を揃えて、cgroupのパラメータをいろいろ変更して値の変動を比べてみた。
実験の条件は以下。
ベンチマーク環境
図の通り。KVM上に構築。ホスト→コンテナは、ベンチ側にルーティングを入れてフォワードしている。また、ホストは32コアCPU(Skylake, 2.3GHz)、196GBのメモリを積んでいる。

ベンチマーク方法
ベンチホストよりコンテナのIPに、以下のパラメータでベンチをかけた。
$ ab -c 300 -t 60 -n 500000 http://10.0.1.2/
コンテナの条件としては、 cpu.max を以下の方法で更新し、$Nの値をmax, 400000 ~ 100000 の範囲で変更する。また cpu.weight は100としている。
$ echo "$N 100000" > /sys/fs/cgroup/lxc/cg2-test-apache/cpu.max
cgroup v1を使ったことのある方なら、2つの値の前者が cfs_quota_us 、後者が cfs_period_us と理解していただければ良さそう。使いうる最大コア数は quota / period で計算ができる。
コンテナ上のミドルは前回と同じApache HTTPD、Debianデフォルトのindex.html。
結果
PSIの計測値は、 /sys/fs/cgroup/lxc/cg2-test-apache/cpu.pressure を1秒ごとに出力して取得した。また、過去10秒間の値を用いた。

quotaが小さいほど当然PSIの値は上がる。逆にいうとcgroupのCPU制限はちゃんと効いていて、今回の場合4コア相当を割り振ればmax(制限なくホストリソースを使う)と変わらないパフォーマンスになるようだ。
(で、今回結果を見ると、前回の実験は条件の記憶違いをしていそう。前回はmaxと書いていたけど、$N=100000でやったのではないだろうか)
LAとの比較
上記と同じ条件で、ホストのLAの上昇も計測した。具体的には1秒ごとに uptime コマンドを発行して計測した。こちらも過去10秒間の値を用いた。

PSIと同じようにベンチ終了とともに下降するのだが、4コア相当($N=400000)を割り振った場合、たとえコンテナの負荷が上がっていてもホストのLA上昇としては検知できない。また、1コア相当($N=100000)の場合、ホストのLAも確かに上昇する(コンテナ内部での処理待ちタスクは間違いなく増えていくと予想される)が、ホスト自体が32コアであるので、高々10 ~ 12程度のLA上昇では静観されてしまう場合もあるだろう。時間の経過でさらに上昇する可能性はあるが、そう考えるとPSIを参照した方が負荷上昇の検知は早くなると考えられる。
今回もCPUバインドなタスクで負荷をかけての検証だったが、前回よりもう少し踏み込んでいじくってみた。
次こそメモリかIOの負荷を掛けてみる。どういうタスクがいいかな...〜