なんとなくバイナリを解析してえ〜と思ったので、mruby 3.2.0 (最新stable?)の .mrb ファイルのフォーマットを眺めることにした。
Rustでパースしました!だとかっこいい、ナウだなと思ったけれど、動的型育ちな自分をどうしても甘やかしてしまい、 Ruby の unpack を軸に解析した。いやほんと、今やRubyで一番使うメソッドでは。
puts "Hello"
mrbファイルにコンパイルするとこうなるらしい。この際、デバッグセクションとLVセクションは無かったことにする。今度ね。
$ ./bin/mrbc --remove-lv tmp/hello.rb $ xxd tmp/hello.mrb 00000000: 5249 5445 3033 3030 0000 0056 4d41 545a RITE0300...VMATZ 00000010: 3030 3030 4952 4550 0000 003a 3033 3030 0000IREP...:0300 00000020: 0000 002e 0001 0004 0000 0000 0000 000a ................ 00000030: 5102 002d 0100 0138 0169 0001 0000 0548 Q..-...8.i.....H 00000040: 656c 6c6f 0000 0100 0470 7574 7300 454e ello.....puts.EN 00000050: 4400 0000 0008 D.....
このバイナリはざっくりとこういう感じで分割される。
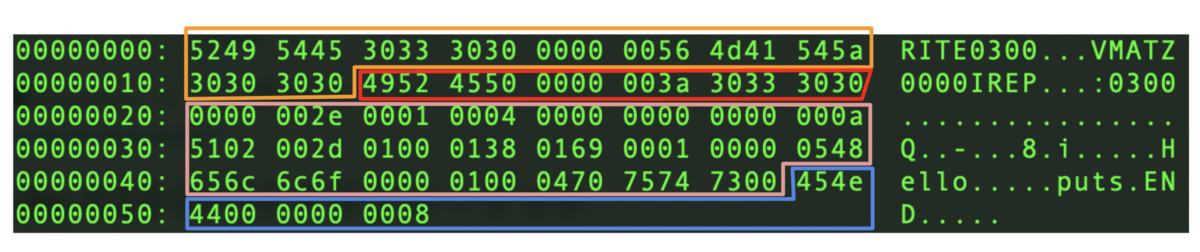
- 最初のオレンジがバイナリヘッダ
- セクションが二つある
- 濃い赤がirepセクションヘッダ
- 薄い赤がセクションボディ
- 青はendセクション(ヘッダのみ)
バイナリヘッダ
/* binary header */ struct rite_binary_header { uint8_t binary_ident[4]; /* Binary Identifier */ uint8_t major_version[2]; /* Binary Format Major Version */ uint8_t minor_version[2]; /* Binary Format Minor Version */ uint8_t binary_size[4]; /* Binary Size */ uint8_t compiler_name[4]; /* Compiler name */ uint8_t compiler_version[4]; };
irbなどを使って簡単に取り出せる。なお、数値であっても uint8_t[4] や uint8_t[2] で扱われ、ビッグエンディアンで解釈される。
data = File.read "tmp/hello.mrb" data[0,20] => "RITE0300\u0000\u0000\u0000VMATZ0000" data[0,20].unpack("Z4 Z2 Z2 I> Z4 Z4") => ["RITE", "03", "00", 86, "MATZ", "0000"]
注目ポイントは compiler_name で、 MATZ 実装以外のコンパイラも将来は...???
irepセクション
mrubyの load.c の実装を見る限り、残りバイト数が sizeof(struct rite_section_header) 未満になるまでバイナリをパースし続ける感じ(なので後ろに短いゴミデータがあっても実は無視される)。
/* section header */ #define RITE_SECTION_HEADER \ uint8_t section_ident[4]; \ uint8_t section_size[4] struct rite_section_header { RITE_SECTION_HEADER; }; struct rite_section_irep_header { RITE_SECTION_HEADER; uint8_t rite_version[4]; /* Rite Instruction Specification Version */ }; // 他のセクションヘッダは実は struct rite_section_header と同様っぽい
セクションの最初4バイトが IREP なら irepヘッダとして処理される。
cur = 20 # sizeof struct rite_binary_header data[cur, 12] => "IREP\u0000\u0000\u0000:0300" data[cur, 12].unpack("Z4 I> Z4") => ["IREP", 58, "0300"]
58 というのはヘッダ先頭からのセクション全体のサイズである。
data[cur, 58] => "IREP\u0000\u0000\u0000:0300\u0000\u0000\u0000.\u0000\u0001\u0000\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000\nQ\u0002\u0000-\u0001\u0000\u00018\u0001i\u0000\u0001\u0000\u0000\u0005Hello\u0000\u0000\u0001\u0000\u0004puts\u0000"
この内容を read_irep_record_1() という関数で前から順番に解釈している。のだが unpack で表現できるので:
# record size, nlocals, nregs, rlen, clen, ilen, data[cur+12..].unpack("I> S> S> S> S> I>") => [46, 1, 4, 0, 0, 10]
ilen が10と分かったので:
data[cur+12+16..].unpack("c10") => [81, 2, 0, 45, 1, 0, 1, 56, 1, 105]
mrbc --verbose の結果と比較すると
1 000 STRING R2 L(0) ; Hello
1 003 SSEND R1 :puts n=1
1 007 RETURN R1
1 009 STOP
mruby/ops.h で順番を数えたけど合ってそう(STRING=81 SSEND=45 RETURN=56 STOP=105)。
残りは pool, syms なんだけど:
data[20+12+16+10..] => "\u0000\u0001\u0000\u0000\u0005Hello\u0000\u0000\u0001\u0000\u0004puts\u0000END\u0000\u0000\u0000\u0000\b"
pool はこういう感じなので:
\u0000\u0001= poolの要素数(1)\u0000= pool内の要素の型(ここではIREP_TT_STR)\u0000\u0005= pool にある文字列の長さ(5、終端文字含まず)Hello\u0000= pool内の文字列
参考:
// in irep.h enum irep_pool_type { IREP_TT_STR = 0, /* string (need free) */ IREP_TT_SSTR = 2, /* string (static) */ IREP_TT_INT32 = 1, /* 32bit integer */ IREP_TT_INT64 = 3, /* 64bit integer */ IREP_TT_BIGINT = 7, /* big integer (not yet supported) */ IREP_TT_FLOAT = 5, /* float (double/float) */ };
残った \u0000\u0001\u0000\u0004puts\u0000 が symsで:
\u0000\u0001= sym数(1)\u0000\u0004= シンボル名の長さ(4、終端文字含まず)puts\u0000= シンボルの文字列表現
とのこと(Cコードを読む限りそう)。
2つ目、かつ最後のセクションは END\u0000\u0000\u0000\u0000\u0008 *1 だけど:
#define RITE_BINARY_EOF "END\0" section_header = (const struct rite_section_header *)bin; // ... else if (memcmp(section_header->section_ident, RITE_BINARY_EOF, sizeof(section_header->section_ident)) != 0) { break; }
こういう感じなので、 struct rite_section_header としてキャストできればOKという番兵な感じ。
mruby のバイナリとOPCODEを解説した本として、Kishima先生の「mrubyバイトコードハンドブック」があるが mruby 2.0.0 対応版である。それでも大変参考になる。
過去の自分を見ていると定期的にバイナリを解析している。次はWASMバイナリを解析するんだと思う。
ということで明日からのRubyKaigi、皆様楽しんでください(唐突)。
*1:\b = \u0008